FREME NER
FREME NER is a named entity recognition tool. It performs entity spotting - spot entity mentions in free texts, entity classification - assigning types from a given knowledge base, entity linking - linking entity mentions with their instances in a given dataset. FREME NER aims at providing support for large variety of languages. Currently, it can perform named entity recognition over texts written in English, German, Dutch, Spanish, Italian, French and Russian.
Table of Contents
Technology Stack
The FREME NER builds on top of mature technologies and appropriately extends them. Following figure illustrates the technology stack.
Entity spotting
Entity spotting is performed based on a Conditional Random Field (CRF) sequence models learned on a large scale training data. As reference implmentation for CRF is used StanfordNER and models for each supported language has been compiled.
Entity classification
Entity classification is supported via 1) external knowledge bases with entity types (e.g., the DBpedia instance types partition), and 2) using CRF classification models trained on large scale labeled data. The CRF models currently are trained on data with four entity types: Person (PER), Location (LOC), Organization (ORG) and Miscellaneous (MISC). The entity types from the external knowledge bases are dependent on the source data and usually these types are more precise and fine-grained. For instance, the DBpedia 2015 ontology encompasses 735 ontology classes (entity types).
Entity linking
FREME NER performs linking of the spotted entity mentions with their representation in a specified knowledge base. Currently, FREME NER integrates several datasets for entity linking including DBpedia, VIAF, CORDIS FP7, ORCID, ONLD, Geopolitical Ontology, and the Global airports dataset. A user using the dataset parameter can specify the dataset to be used for entity linking.
The current entity linking approach is relying on a most-frequent-sense method, where the entity is linked with the most common entity for the list of candidate entities. The current implementation is using Apache Solr for the candidate generation.
Core features
Domain specific NER
FREME NER exlusively provides domain specific adoption. A user using the domain parameter can specify the domain of interest and only entities from that domain will be returned. FREME NER is using TaaS as domain classification system and it supports following domains: TaaS-2007 Sports, TaaS-1510 Tourism, TaaS-0303 Finance and accounting, TaaS-0200 Law, TaaS-0305 Marketing and public relations, TaaS-2303 Literature, TaaS-0100 Politics and Administration, TaaS-0300 Economics, TaaS-1000 Agriculture and foodstuff, TaaS-1005 Foodstuff, TaaS-2000 Social sciences, TaaS-2001 Education, TaaS-2002 History, TaaS-2005 Culture and religion, TaaS-2006 Linguistics, TaaS-2300 Arts, TaaS-2302 Music, TaaS-2304 Dance, TaaS-1500 Industries and technology, TaaS-1502 Chemical industry, TaaS-1509 Transportation and aeronautics, and TaaS-2200 Medicine and pharmacy.
Dataset specific NER and datasets management
Proprietary datasets can be easily integrated in FREME NER and further used for entity linking. Thus, FREME NER provides dataset management API. A user can upload his/her dataset and then perform entity linking using this dataset. This allows users to integrate custom datsets.
Entity filtering
While in some cases a user is interested in recognition of all the entities, in some cases a user would like to spot entities only of a specific types. Only organizations, or project names. For this purpose, FREME NER implements an entity filtering feature using the types parameter. A user can submit his/her content and specify the list of entity types that are of his interest.
Multilingual support
FREME NER can provide entity recognition in texts written in different languages. Currently, FREME NER suppors following set of languages: English, German, Dutch, Spanish, French, Italian and Russian.
Dependencies
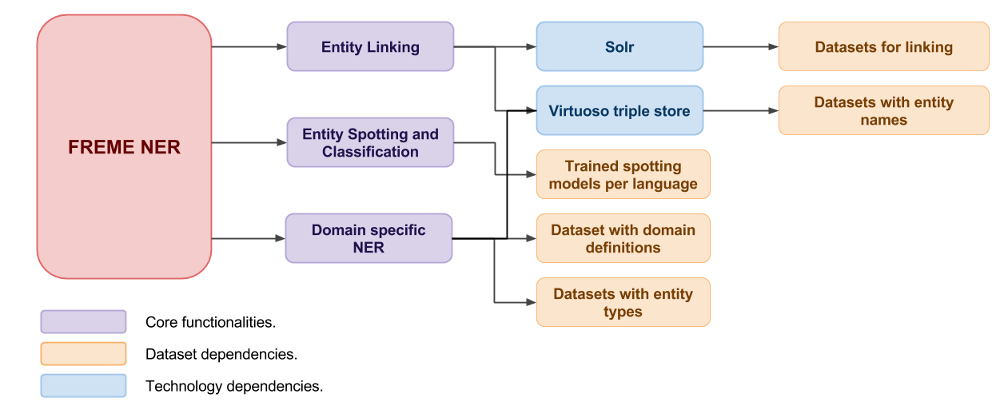
The following figure illustrates the dependencies of FREME-NER.
How to install
Prerequisites
- FREME NER runs as a FREME Package, so it requires these prerequisites.
- It needs access to a running Solr Server. To set up a Solr Server at your machine, do the following:
- Here you can download the Solr Server distribution archive. This will install Solr Version 5.2.1.
- Extract this file to your preferred directory
- Furthermore, install the Virtuoso triple store
- Download the distribution archive This will install Virtuoso 7. You need at least this version of Virtuoso.
mv virtuoso-opensource-7.2.4.2.tar.gz /opt/cd /optsudo tar -xvf virtuoso-opensource-7.2.4.2.tar.gzcd /opt/virtuoso-opensource-7.2.4.2/./configuremakemake install- When you specify prefix=’some_directory’ in the next command, Virtuoso will be installed to that directory otherwise it will be installed in the default directory which is: /usr/local/virtuoso-opensource/
make install prefix=/opt/virtuoso
After installation the web admin interface is at http://localhost:8890/conductor and the SPARQL endpoint at http://localhost:8890/sparql. The initialising FREME-article explains how you can load FREME data into the Virtuoso Triple Store and the Solr Server.
- A domain entity mapping file as CSV: Here you can get the one currently used by FREME. This file contains several domains, e.g. Sports or Tourism, which can be used to narrow the output from e-entity down to entities from the specified domain only.
- Trained NER model files for the languages you want to support. The models are licensed under the Creative Commons Attribution-ShareAlike 3.0 license. They were created using the dbpedia abstracts corpus.
Get the FREME NER package
Clone this https://github.com/freme-project/freme-packages.git to your machine and and build the package by executing mvn package in the folder freme-ner-dev, as described here.
FREME NER Configuration options
The configuration options of FREME NER are located in the e-Services article.
If you have done all the steps above, you can start FREME NER.
OPTIONAL: Configure the package
To set up a further customised FREME NER you have to create a FREME package by your own as described in this article.
In a short, you have to create a pom.xml, a package.xml and a application.properties (like the one you have already created in the previous paragraph) file.
A minimal FREME NER pom.xml has to contain the following:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<artifactId>your-freme-ner</artifactId>
<version>0.1-SNAPSHOT</version>
<parent>
<groupId>eu.freme.packages</groupId>
<artifactId>package-parent</artifactId>
<version>0.2</version>
</parent>
<dependencies>
<dependency>
<artifactId>FremeNER</artifactId>
<groupId>eu.freme</groupId>
<version>0.6</version>
</dependency>
</dependencies>
</project>
This pom.xml includes the FremeNer e-service dependency and the FREME repositories.
Here is the content of a minimal FREME NER package.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<import resource="classpath:spring-configurations/freme-ner.xml" />
<import resource="classpath:spring-configurations/freme-common.xml" />
</beans>
freme-ner.xml adds the FremeNER e-service.
freme-common.xml contains common FREME code needed by every FREME package.
Of course you can add any FREME service you need, have a look at the FREME basic-services list or the FREME e-services list. In any case, just add the maven dependency to your pom.xml and import the related spring configuration file via your package.xml by adding <import resource="classpath:spring-configurations/SPRING-CONFIGURATION-FILENAME" />.
Now you can create a binary distribution and start FREME NER.
Working with the FREME NER source code
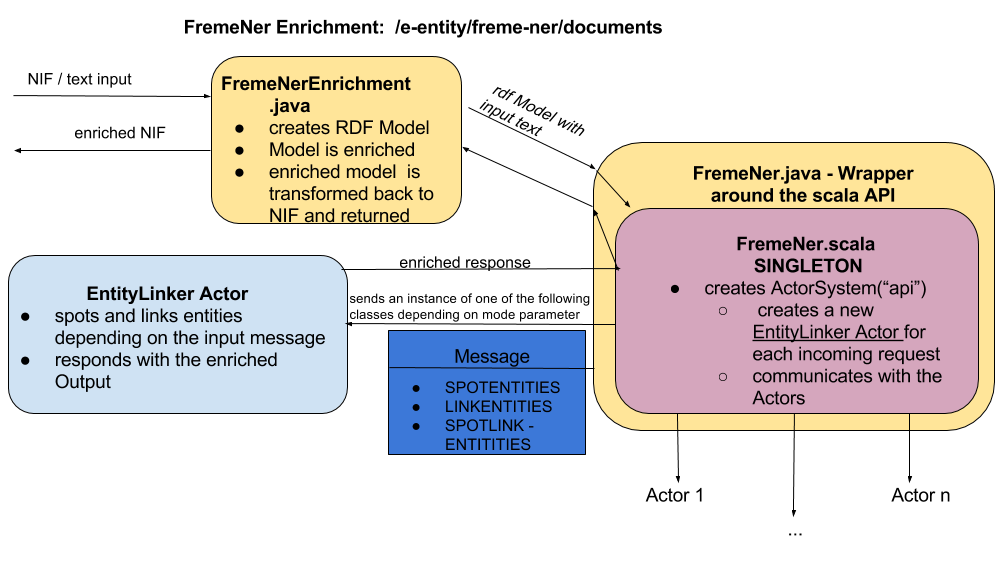
If you want to have a look at the source code of FREME NER, check out its underlying e-service at GitHub. FREME e-services are not executable by its own, they need to be part of a FREME package like the freme-ner package. Consult the FREME architecture article to dive deeper into this topic. The following figure illustrates how FREME NER implements text enrichment.
Tips
Speed up the processing
Not always one need to perform entity spotting, linking and classification. In some cases a user might be interested only in spotting the entity mentions, while in some cases, spotting the entity mentions and linking them to a specified dataset. FREME NER provides the mode parameter which can be used to instruct FREME NER on the level of processing, e.g. by setting mode=spot,link, FREME NER will spot and link entites. If the parameter is set to mode=spot,link,classify it will perform entity spotting, linking and classification. Following combinations are possible: 1) spot; 2) spot,classify; 3) spot,link; 4) spot,link,classify; 5) link; and 6) link. You can this feature via the client at our API documentation page.
Linking of single entities
In some cases, a user might want to disambiguage and retrieve a link for an entity from a specified dataset. Such feature is also possible with FREME NER. In order to perform linking of a single entity, a user should set mode=link and informat=text and sent as input the name of the entity. FREME NER will disambiguate and link the entity to the specified dataset.
Understand why some entites are not spotted?
Sometimes users might wonder why some entities in texts such as “hello world abc berlin” are not spotted - “berlin” not spotted as an entity. Note that such behaviour is related to the trained model for entity spotting. Our entity spotting models have been trained on clean text which means correct grammar, correct spelling (including capitalization), correct punctuation marks, no HTML or XML markup, etc. Therefore, the entity spotting will work most precisely, if clients submit “clean” and “proper” texts.